Azure Chaos Studio is a new managed service (in public preview now GA!) by Microsoft. It allows you to inject real-world faults into your Azure infrastructure via a controlled experiment. This is an awesome tool to help test service resiliency in a controlled manner, whether that is high CPU or mimicking a network outage.
Currently as this in public preview it is likely to be constantly evolving and at the time of writing it seems that it is temporarily free of charge to use until it exits public preview, then it will move onto a Pay-As-You-Go style pricing table based on execution.
There are a lot of other fault metrics you can inject and experiment with:

However, todays guide will cover the setup and configuration of a high CPU Chaos experiment on my Azure domain controller.
Prerequisites
- Register the Microsoft.Chaos resource provider in the subscription you are wanting to run experiments within.
- Create a managed identity. This is to enable agent-based experiments against the object. Without this, you will only be able to execute service direct based experiements.
Enable the Chaos Studio targets
Firstly, in the portal, go to Chaos Studio and select the Targets under the Experiment management to view your resources.
Secondly, select the resource(s) you wish to run the experiments on, then click Enable targets. There are more guidance and information on the agents and setup on the Microsoft docs.

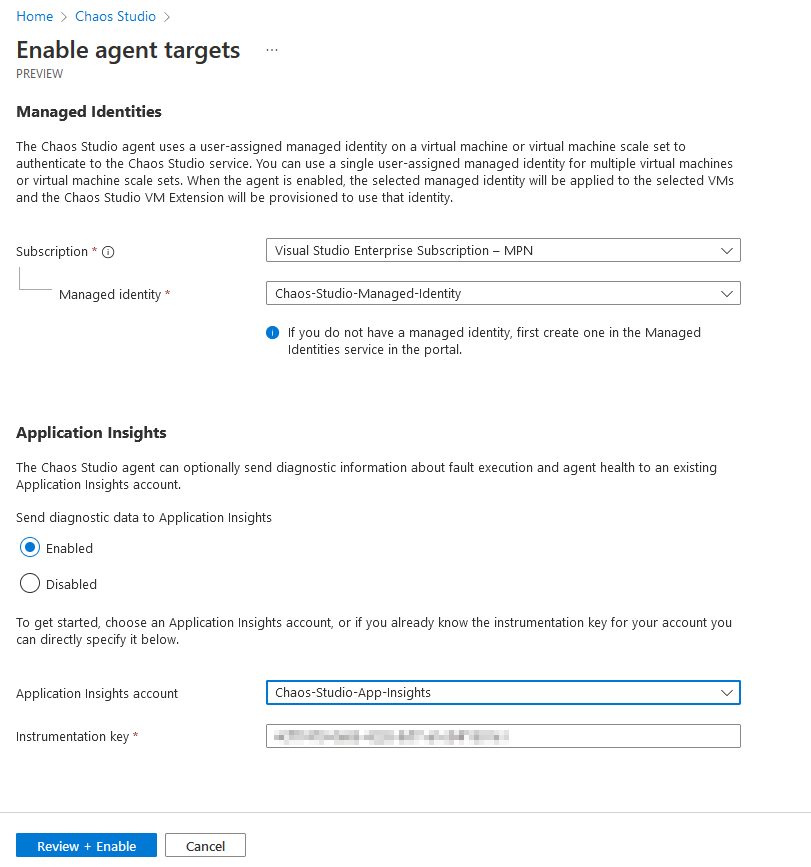
When enabling the agent target select the managed identity that was setup.
Optionally, you can create an Application Insights to log diagnostics data into if you wish but it is not mandatory. Now we’re nowready to create an experiment!
Creating the experiment
Next up, go to the Experiements tab and click Create to begin configuring the chaos experiment. The rest is self explanatory in this section.
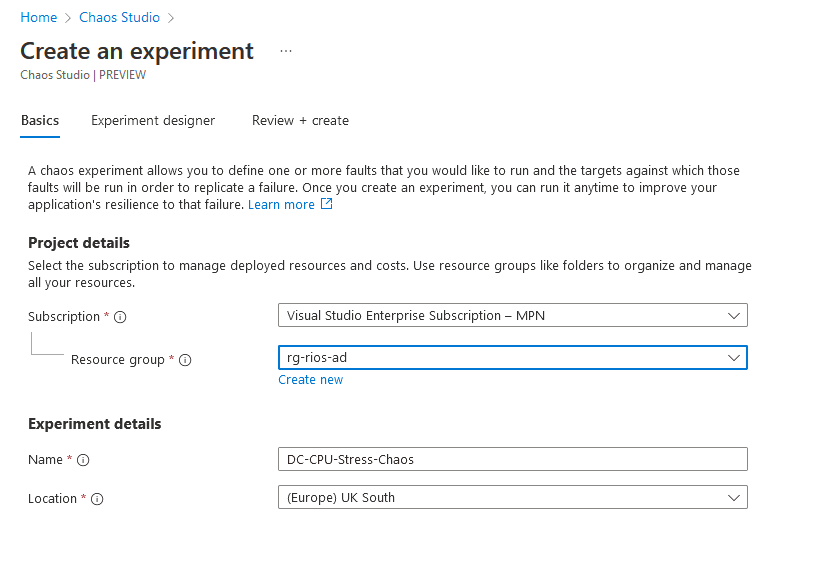
Now it’s time to design the experiment itself in the Chaos Studio designer. Here is where you can set your paramater faults and delays to mimick the scenario you require.
In my example, I’m going to run CPU at 80% for a duration of 30 minutes, then add a delay of 10 minutes before proceeding again at 99% CPU for 5 minutes. However, here you can add any steps you wish from high memory, disk IOPS test all the way to network outages!
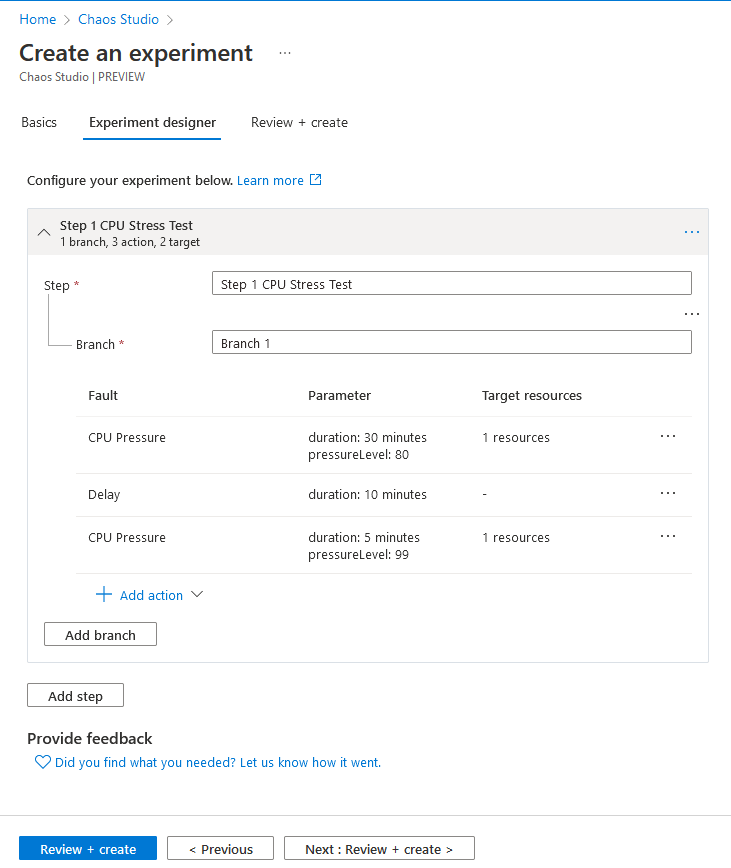
Granting permissions for the managed identity
When the Chaos Studio experiment is created, it will also create a system managed managed identity in Azure.
Next you’ll need to assign the appropriate permissions (VM contributor in this example) on the object you’re going to be running the experiment on for it to run successfully. Then select the managed identity like below.
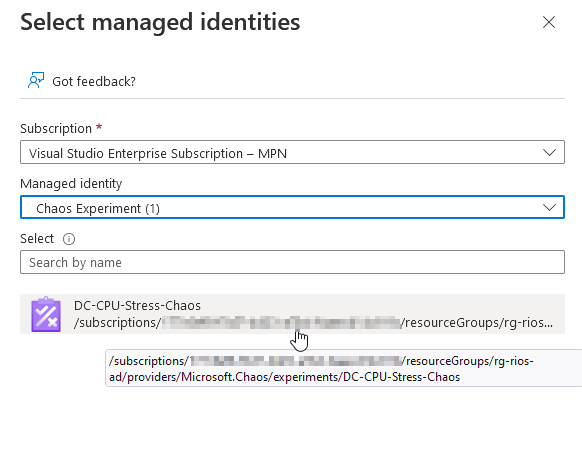
Running the experiment
Lastly, click Start experiment(s) to run the experiment and await for the test to complete.
During this you can review the details of the job and what stage it is currently running through on the Chaos Studio page.
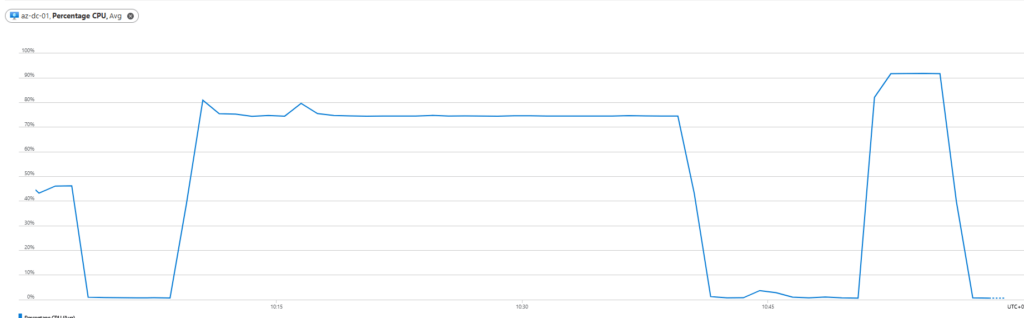
I can see the virtual machine CPU graph shows the 80% stress followed by the delay and ramp back up to 99% for the last 10 minutes.
Here’s also how the objects look like in the resource group after creation.

How much did it cost?
After checking the cost analysis breakdown over 24 hours later, it appears the service is still temporarily free of charge whilst within the preview scope During Microsoft Ignite November 2023, Chaos Studio went GA and is now following a per-action minute pricing table. Even though it states on or after April 2022 it would move to an execution style based PAYG costing so I would anticipate this to happen very shortly.
Conclusion
This is going to be a game changer for testing your cloud resiliency and allowing teams to stress-test new (and existing!) solutions prior to going live to further enhance performance and redundancy of services.
I think it’ll also be a great way to understand where infrastructure or applications may have bottle necks or potential flaws that can be observed and enhanced from the Azure Chaos Studio experiments.
It’s also really simple and easy to set up and to create a flow of experiment faults.
References:
https://docs.microsoft.com/en-us/azure/chaos-studio/
Azure Chaos Studio – Chaos engineering experimentation | Microsoft Azure
Hi, I am trying to use the chaos studio to simulate a network latency on a VMSS node. Do you know how I can confirm if my test is working as expected ?
Hi there. When the experiment is running you should be able to go to the nodes and review the monitoring metrics to review network related metrics and notice the spike or delay in latency.
Can we use Azure Chaos Studio to simulate a DDoS Attack to our Azure Application?
I don’t believe so, you can view the full supported scenarios here: https://learn.microsoft.com/en-gb/azure/chaos-studio/chaos-studio-fault-library